Methodisches Vorgehen beim Monitoring (MATR Nr. 5)
1. Zur Genese der Telegram-Netzwerke
Das Monitoring der Forschungsstelle auf Telegram geht von einem akteursbasierten Ansatz aus. Das heißt, dass relevante digitale Sphären für demokratiefeindliche Kommunikation über eine Vorklassifizierung von identifizierbaren Akteuren eingegrenzt werden. Sie dienen als Startpunkte für die Sichtung breiterer Dynamiken und als Knotenpunkte für Protestmobilisierung. Ausgehend von einem Set von 269 qualitativ durch zwei Expert*innen klassifizierten Akteuren, die im öffentlichen Diskurs durch ihre Agitation Sichtbarkeit erhalten haben, wurden Charakteristika wie ideologische Ausrichtung auf Grundlage des Kommunikationsverhaltens und der bekannten Offline-Positionierungen der Akteure sowie Formen der Organisierung festgelegt, um das Feld zu sondieren. Zudem wurde die Verbindung zu breiteren Netzwerken markiert, bspw. im Falle von reichweitenstarken Accounts, die für breitere Bewegungen sprechen. Ausgehend von dieser manuellen Einordnung, die durch eine externe Expertise von Karolin Schwarz vorgenommen und von den Mitarbeitenden der Forschungsstelle geprüft worden ist, wurde ein automatisiertes, mehrstufiges Snowball-Sampling auf der Plattform Telegram durchgeführt.
1.a. Klassifizierung der Akteure
Aus dem Snowball-Sampling wurden für die Plattform Telegram 4.584 öffentlich kommunizierende Kanäle und Gruppen – im folgenden beides unter »Accounts« zusammengefasst – aufgenommen, die sich durch Weiterleitungen von plattforminternen Beiträgen in das Netzwerk einfügen. Bei Telegram haben Kanäle eine einseitige Richtung der Kommunikation (One-to-Many-Kommunikation), während in Gruppen sich jede mit jedem per Chat austauschen kann. Letztere sind in ihrer Ausrichtung divers, weswegen sie zur besseren Analyse ein weiteres Mal klassifiziert wurden, um eine Einordnung über die ideologische Ausrichtung und Verschiebung ihrer Positionierung im Diskurs treffen zu können. Hierzu wurden Accounts anhand ihrer Subscriber und Zentralität im Netzwerk sortiert und die ersten 1.400 auf ihr Kommunikationsverhalten geprüft. Hinzu kommen weitere Accounts, welche im journalistischen oder wissenschaftlichen Diskurs bereits behandelt wurden. Die qualitative Einordnung der Accounts in zuvor definierte Kategorien (s.u.) umfasste den Einblick in die letzten 20 Posts und die 20 zuletzt geteilten Links des Kanals und wurde durch das Fachwissen der Expert*innen der Forschungsstelle abgeglichen. Zudem wurden Kanäle, die sich in ihrer Selbstbeschreibung oder über die Nutzung einschlägiger Codes der Querdenken-Bewegung oder dem QAnon-Verschwörungskult zuordnen, in die jeweiligen Kategorien eingeordnet. Ähnliches gilt für Reichsbürger, die einen markanten Außenauftritt haben. Die Klassifizierung soll in der Zukunft weiter ausgebaut werden. Bezugnehmend auf bestehende Forschungsliteratur wurden in einer idealtypischen Klassifizierung die folgenden Ober- und Unterkategorien unterschieden:
Rechtsextremismus:
- Neonazismus: Dessen Anhänger*innen zeichnen sich durch einen positiven Bezug auf den Nationalsozialismus und ein rassistisch strukturiertes Weltbild aus. Viele Anhänger sind Teil von Subkulturen, in denen über Musik, Kampfsport und Hooliganismus ein Zugang zu neonazistischem Gedankengut geliefert wird.
- Reichsbürger: Eine Gruppe von Menschen, die davon ausgeht, dass das Deutsche Reich nie aufgelöst wurde und die immer noch bestehende legitime Herrschaftsform sei. Die bundesdeutsche Demokratie habe keine repräsentative Funktion, sei nicht souverän, sondern von fremden Mächten gesteuert.
- Extreme Rechte: Organisationaler Zusammenhang, der die liberale Demokratie abschaffen will. Ihre Ideologie beruht auf Ungleichwertigkeit und Autoritarismus.
- Neue Rechte: Ein strategisch denkender Kreis rechtsextremer Aktivist*innen, die über kulturelle Aktivitäten politische Macht aufbauen wollen. Ihre Wortführer*innen inszenieren sich als ideologische Vordenker*innen. Parteien und Bewegungen werden von ihren Vertreter*innen strategisch beraten.
- Populistische Rechte: Eine Sammelkategorie, in der islamfeindliche und rassistische Akteure mit einem rechten Weltbild eingeordnet werden. Es wird das ehrliche Volk gegen eine korrupte Elite gestellt. Das System soll aber demokratisch umgestürzt werden.
Konspirationismus:
- Verschwörungsideologie: Eine Oberkategorie für Akteure, die den Lauf der Geschichte durch eine Aneinanderreihung von Verschwörungen versteht, weshalb prinzipiell alles hinterfragt wird und ein schlichtes Freund-Feind Bild entsteht. Das Verschwörungsdenken übersetzt sich in politische Mobilisierung.
- Corona-Desinformation: Umfasst Akteure, die im Kontext der Corona Pandemie mit skeptischen oder leugnerischen Positionen in den öffentlichen Diskurs treten. Sie nutzen ihre öffentlichen Kanäle meist monothematisch.
- Esoterik: Eine weltanschauliche Strömung, die durch Heranziehung okkultistischer, anthroposophischer sowie metaphysischer Lehren und Praktiken auf die Selbsterkenntnis und Selbstverwirklichung des Menschen abzielt.
- QAnon: Meint einen verschwörungsideologischen Kult, der sich um falsche Behauptungen dreht, die von einer anonymen Person (bekannt als »Q«) aufgestellt wurden. Ihre Erzählung besagt, dass satanische, kannibalistische Eliten einen globalen Ring für systematischen Kindesmissbrauch betreiben. Entstanden während Trumps Präsidentschaft wird von einem tiefen Staat ausgegangen, der die Regierung kontrolliere.
- Querdenken: Mitglieder und Sympathisant*innen einer Bewegung, die sich im Kontext der Proteste gegen die Covid-19-Pandemie gegründet hat und Zweifel an der Rechtmäßigkeit der Maßnahmen zur Eindämmung mit einer radikalen Kritik an demokratischen Institutionen verbindet.
- Anti-Mainstream-Gruppen: Ohne klare Zielsetzung. Sie setzen ihre Akzente alternierend zu dem, was als stark grün geprägter Mainstream wahrgenommen wird, und haben sich oft aus Querdenken-Gruppen heraus entwickelt.
Sonstiges:
- Russischer Imperialismus: Insbesondere russische Akteure, die den Aufbau eines russischen Reichs propagieren und den Krieg in der Ukraine befürworten.
- Pro-russische Propaganda: Kanäle, die pro-russische Propaganda betreiben und einseitig über den Krieg in der Ukraine berichten.
- Prepper: Eine Gruppe Personen, die sich mittels individueller oder kollektiver Maßnahmen auf verschiedene Arten von Katastrophen vorbereiten und nicht selten Phantasien des Umsturzes pflegen.
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
Anzahl der kategorisierten Kanäle in Ideologie und Ideologiegruppe. Die Farbgebung wird nach Möglichkeit in allen visuellen Elementen beibehalten.
Viele der identifizierten Kanäle lassen sich mehreren Kategorien zuordnen. So ist es nicht leicht, Verschwörungsideologien von rechtsextremen Netzwerken zu isolieren. Auch pflegen lokale Ausprägungen bestimmter Bewegungen unterschiedliche Bündnispolitiken oder nutzen bestimmte Affiliationen, um sich einem öffentlichen Stigma zu entziehen. Ausschlaggebend für die Klassifizierung war ein kumulatives Verfahren, wonach geprüft wurde, ob Akteure, die Verschwörungsmythen teilen, auch offensichtlich mit rechtsextremen Accounts verbunden sind. Ist dies der Fall, fällt die Entscheidung auf die extrem rechte Kategorie. Wenn allerdings bekannt ist, dass bspw. einzelne Influencer sich stärker ein eigenes verschwörungsideologisches Profil aufbauen, um sich von organisierten rechtsextremen Strukturen zu distanzieren oder eine bestimmte Verschwörungstheorie besonders prägnant ist, wird hier eine Unterkategorie des Konspirationismus gewählt. Um einen individuellen Bias zu reduzieren wurden die 269 Seed-Accounts von zwei Expert*innen gemeinsam kategorisiert. 145 Accounts wurden von der weiteren Auswertung ausgeschlossen, da sie nicht in das potenziell demokratiefeindliche Spektrum gehören.
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
Anzahl der betrachteten Nachrichten nach der Ideologie der Kanäle und Gruppen für den Zeitraum dieses Trendreports.
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
Anzahl der betrachteten Nachrichten nach der Ideologie der Kanäle (ohne Gruppen) im Zeitverlauf.
Die Anzahl der Nachrichten pro Ideologie ist sehr heterogen. QAnon und andere Verschwörungsideologen senden sehr viel mehr Nachrichten als andere Ideologien.
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
Auf der X-Achse sind die Anzahl der Kanäle, welche von groß nach klein geordnet waren. Auf der Y-Achse ist der kumulierte Anteil der Gesamtnachrichten von den Top-X-Kanälen. Zum Beispiel: Die Top-4 der Querdenken-Kanäle sind für 53% der Nachrichten verantwortlich.
Neben der Anzahl der Nachrichten ist es für die Interpretation der Datenauswertung interessant, welcher Anteil der Nachrichten sich auf wenige Kanäle konzentriert. Den Ideologien Prepper und Russischer Imperialismus sind nur wenige unserer Kanäle zuzuordnen, daher können auch nur begrenzt Aussagen für die Gruppen getroffen werden. Bei Reichsbürger, Neue Rechte, Pro-Russische Propaganda und Neonazismus werden über 80% der Nachrichten von den 10 Top-Kanälen gesendet. Die Dominanz dieser Akteure wird bei Datenauswertungen beachtet: zum Beispiel wird für ausgewählte Analysen der zusammengefasste Rechtsextremismusbereich betrachtet.
1.b. Analyse der Kommunikationsnetzwerke im Untersuchungszeitraum
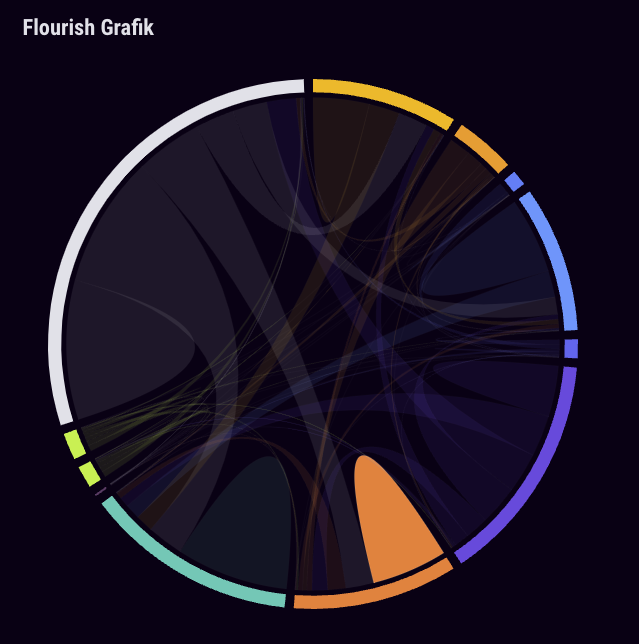
Um die Kommunikationsnetzwerke auf Telegram im Untersuchungszeitraum, also von September 2023 bis November 2023, zu analysieren und die Interaktionen der jeweiligen Akteursgruppen darzustellen, haben wir ein cross-sektionales Chord-Diagram erstellt. Dieses zeigt das Weiterleitungsverhalten der oben genannten politische Milieus in absoluten Zahlen ohne Berücksichtigung endogener Effekte. Netzwerkknoten sind hier die jeweiligen Milieus aggregiert.
Darüber hinaus haben wir ein Netzwerkinstanz gebildet, um auch das Weiterleitungsverhalten auf Akteursebene darstellen und analysieren zu können. Die individuellen Akteure wurden nach ihrer Ideologie eingefärbt und Verbindungen stellen deren Weiterleitungen von Telegraminhalten dar. Akteure, die wir nicht klassifiziert haben, bzw. die für uns von nachgelagertem Interesse sind, sind anonymisiert und grau hinterlegt.
2. Zur Genese der Themenmodelle
2.a. Algorithmus
Zur Berechnung der Themen haben wir die latente Dirichlet-Zuordnung genutzt (LDA). Im Gegensatz zu komplexeren Methoden – wie in (5.) beschrieben – lässt sich diese Methode mit vertretbarem Aufwand für große Textmengen einsetzen und erhält daher den Vorzug für das allgemeine Themenmodell.
Der LDA berechnet zu einem gegeben Korpus und einer gewünschten Themenzahl k eine Wahrscheinlichkeitsverteilung für alle Wörter im Korpus für jedes der k Themen. Dafür wird jedes Dokument als eine Bag-of-Words betrachtet, bei dem ausschließlich das Vorkommen einzelner Wörter von Bedeutung ist, während die Wortreihenfolge und die Satzzusammenhänge für die Klassifikation von Themen keine Rolle spielen. Jedem Dokument wird die Eigenschaft zugeschrieben, aus mehreren latenten Themen zu bestehen. Ein Thema ist schließlich durch eine Wahrscheinlichkeitsverteilung von Wörtern definiert.
Das prinzipielle Verfahren beginnt mit der zufälligen Zuweisung von jedem Wort im Korpus zu einem Thema. Danach folgt eine Schleife über alle Wörter in allen Dokumenten mit zwei Schritten: Mit der Annahme, dass alle anderen Wörter außer das aktuelle korrekt ihren Themen zugeordnet sind, wird die bedingte Wahrscheinlichkeit p(Thema t | Dokument d) berechnet: Welche Themen kommen im Dokument wahrscheinlich vor? Das zurzeit betrachtete Wort passt mit höherer Wahrscheinlichkeit zu diesen Themen. Also:
- Berechnung der bedingten Wahrscheinlichkeit p(Wort w | Thema t): Wie stark ist die Zugehörigkeit des Wortes zu den Themen?
- Aktualisieren der Wahrscheinlichkeit, dass ein Wort zu einem Thema gehört: p(Wort w ∩ Thema t) = p(Thema t | Dokument d) * p(Wort w | Thema t).
Durch mehrere Iterationen über alle Wörter im Dokument erreicht der Algorithmus eine stabile Konfiguration von Wortwahrscheinlichkeitsverteilungen für k Themen.
2.b. Datengrundlage und Preprocessing
In die Themenmodellberechnung sind alle Nachrichten der in Abschnitt 1.a genannten Kanäle eingegangen. Es erfolgte die Bearbeitung mit folgender Preprocessing-Pipeline:
1.Filtern der NA-Texte: Nachrichten, die nur aus Medien-Dateien bestehen, ohne weiteren Text zu enthalten, wurden in der Themenmodellierung nicht berücksichtigt.
- Filterung auf den Zeitraum vom 1. Juni 2022 bis 30. August 2023.
- Filter auf > 50 Zeichen: Eine erste Filterung auf die Mindestanzahl von Zeichen ist nötig, um eine Spracherkennung durchzuführen.
- Filter auf deutschsprachige Nachrichten: Dafür wurde die Bibliothek Polyglot verwendet.1
- Preprocessing der Texte
- Entfernung der URLs mittels Regular Expressions.
- Lemmatisierung, also die Reduktion der Wortform auf ihre Grundform, mit spaCy bei Verwendung der Pipeline de_core_news_lg.2
- Entfernung von Stoppwort-Lemmata anhand verschiedener Stoppwortlisten.
- Entfernung von Wörtern mit dem Vorkommen < 8.
- Entfernung Sonderzeichen.
- Filter auf 1-n Kanäle: Die Nachrichten innerhalb der Chatkanäle behandeln oft keine Themen im gewünschten Sinn und verschlechtern die Nutzbarkeit des Themenmodells. Die Texte werden dennoch später klassifiziert, um die Ergebnisse explorativ nutzen zu können.
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
2.c. Modellberechnung und Themenbestimmung
Für das Training des Modells haben wir das Python-Paket tomotopy genutzt. Der wichtigste Parameter beim Training des LDA ist die Anzahl der zu findenden Themen. Dieser Prozess ist mit einigen Freiheitsgraden behaftet, der schließlich auf einer Interpretationsleistung der Forschenden basiert. In der Regel werden Themenmodelle mit einer Reihe von verschiedenen Themenzahlen trainiert und für jedes Thema wird eine Themenkohärenz berechnet. Anhand dieser wird abgeschätzt, wie viele Themen in etwa genügen, um das Themenspektrum im Korpus abzudecken. In diesem Trendreport haben wir uns auf die gesammelte Erfahrung aus dem vorherigen Trendreport verlassen und erneut 120 Themen verwendet. Der vollständigkeitshalber wird die Herangehensweise im folgenden Paragraph erneut beschrieben.
Es wurden zwei gebräuchliche Metriken für die Modellkohärenz berechnet, welche im folgenden Graph zu sehen sind.4
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
Die Kurven der Koherence geben dem Anwender einen Anhaltspunkt für die Bestimmung der Modellgüte zur Hand, aus dem sich in diesem Fall keine eindeutige Empfehlung ableiten lässt.5 Prinzipiell ist es bei einer großen Menge von Daten möglich, die Anzahl der Themen relativ frei zu wählen, mit dem naheliegenden Trade-Off zwischen potentiell unspezifischen Themen bei einer kleinen Anzahl von k und spezifischen, aber teilweise redundanten Themen bei großer Anzahl von k. Wir haben uns für die große Themenanzahl k=120 entschieden, da somit eine große Anzahl der aus substantieller Sicht erwartbaren Themen Niederschlag im Modell finden.6
Allerdings benötigt die qualitative Einordnung der Themen dementsprechend viel Zeit. Für diese wurden im Vier-Augen-Prinzip die 25 Wörter mit höchster Wahrscheinlichkeit und die 25 Wörter mit auf gesamtwordhäufigkeit-normierter Wahrscheinlichkeit betrachtet. Erstere zeigen die generelle Beschaffenheit des Themas, wobei zweitere die spezifischen Wörter zeigen, welche die Abgrenzung zu anderen Themen deutlich machen.
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
Bei der Verwendung von einem LDA-Themenmodell gilt es zu beachten, dass der Algorithmus keine Möglichkeit hat, Dokumente oder Wörter auszuschließen. Das heißt, jedes Dokument bekommt Themen und jedes Wort wird Themen zugeordnet. Zwangsläufig entstehen auch Wortverteilungen, welche sich nicht einem Thema im herkömmlichen Sinne zuordnen lassen, wie beispielsweise das Thema Sprache_Füllwörter (siehe Wordclouds). Eine weitere Schwierigkeit sind überlappende Themen wie die zwölf Themen rund um Corona. Hier ist es für eine aussagekräftige Interpretation essentiell, eine sinnvolle Einordnung der Themen vorzunehmen. Dafür haben wir in einem iterativen Prozess die Themen in acht Themenkomplexe und 36 Oberthemen aufgeteilt.
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
Die Entwicklung aller Themen wird in folgender Grafik gezeigt:
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
Für eine erste Einschätzung der Güte der Einteilung diente die Korrelationsmatrix zwischen den Wortwahrscheinlichkeiten der verschiedenen Themen. Die Achsen sind zur Übersichtlichkeit mit den Themenkomplexen gekennzeichnet. Jede Zeile zeigt die Korrelation für ein Thema mit allen anderen Themen. Ein weißer Punkt bedeutet vollständige Korrelation. Je dunkler der Punkt, umso weniger korrelieren die Themen. Es lassen sich Cluster von Themen erkennen, die uns bei der Einteilung als Stütze dienen können. Beispielsweise befindet sich etwa unten rechts auf der Diagonale das Thema Ukraine-Russland.
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
2.d. Validierung der Themen
Die Erkennung eines Themas in einem Dokument ist instabil für kürzere Dokumente.7 Zur Annäherung an eine Stabilitätseinschätzung in Abhängigkeit von der Dokumentenlänge führten wir folgende Untersuchung durch:
- Auswahl eines zufälligen Samples von 25.000 Dokumenten mit einer Lemmata-Anzahl von über 100: Die Themenermittlung zu diesen Texten wird als korrekte Referenz gesehen, da der LDA für diese Textlänge sehr stabil ist.
- Wir betrachten verschiedene Textlängen von n = 10 bis 100 in Zehnerschritten: Es werden für jedes Dokument n Lemmata aus der jeweiligen Ursprungsmenge gesampelt. Für die entstehende Wortmenge wird ein Thema inferiert, so dass eine neue Themenzuweisung für die 25.000 Dokumente entsteht. Für ein stabiles Themenmodell sollte diese Zuweisung möglichst nahe an der Referenz aus Schritt 1 liegen.
- Zehnfache Wiederholung von Schritt 2 und Aggregation der Ergebnisse: Das resultierende Thema wird über den Modalwert ermittelt. Zusätzlich werden die Oberthemen und Themenkomplexe bestimmt, um zu sehen, ob das Thema in der weiter gefassten Definition noch erfasst wird. Schlussendlich wird die euklidische Distanz zwischen den Wortwahrscheinlichkeitsverteilungen des Referenzthemas und des gesampleten Themas ermittelt, welches als Abstandsmaß unabhängig von der Kategorisierung ist und daher verlässlicher.
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
Die Ellenbogenmethode legt nahe, dass die Anwendung des Modells für Texte ab der Lemmatalänge von 20 einen guten Trade-Off zwischen Dokumentenanzahl und dem zu erwartenden Fehler bei der Themenbestimmung kürzerer Texte darstellt. Bei den Themenkomplexen sind im Schnitt nur 16 Prozent Fehler bei dieser Dokumentenlänge zu erwarten. Vor dem Hintergrund, dass unsere Auswertung zumeist auf stark aggregierten Daten basiert, ist dieser Fehleranteil vertretbar.
Weiterhin interessant ist die Beobachtung, dass der Fehler selbst bei der gesampelten Dokumentenlänge von 100 bei zehn Prozent für die Hauptkategorien liegt. Dies verdeutlicht, dass selbst ausreichend lange Dokumente eine gewisse Unsicherheit in dem zugewiesenen Thema beinhalten. Indem die Anzahl der Fehlzuweisungen aggregiert und durch die Prävalenz geteilt wird, bekommen wir einen normierten Prozentfehler für die Kategorien.
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
Aggregiert ergeben sich für die Hauptkategorie folgende Fehlerprozente: Sonstiges 19,8%, Politik 11,5%, Weitere Themen 11,3%, Protestbewegung 10,5%, Weitere Themen 10,1%, Verschwörung 8,2%, Ukraine-Russland 6,9%, Corona 4,6% und Esoterik 3,3%. Der häufigste Fehler ist der Übergang von Sonstiges zu anderen oder umgekehrt. Dies ist ein nachvollziehbarer Fehler, da Sonstiges die Sprachmuster enthält und diese zu einem Teil in jedem Text vorzufinden sind. Insgesamt sind das gute Werte. Für die Interpretation sollte dennoch beachten werden, dass die Themen Politik und Protestbewegung im Vergleich zu inhaltlich klarer abgrenzbaren Themen eine höhere Fehlerquote mit sich tragen.
3. Zur Analyse der Memes
Das Ziel der Studie ist es, Aussagen über die Verbreitung von visuellem Hass auf einer breiten Datengrundlage treffen zu können und visuelle Mittel zu identifizieren, die zur gruppenbezogenen Abwertung eingesetzt werden. Der visuelle Turn in der Kommunikation von digitalem Hass ist bereits vielfältig diskutiert worden. In der Untersuchung von visuellem Online-Hass haben sich insbesondere Big Data Ansätze hervorgetan, die auf einer Grundlage über automatisierte Bilderkennungen und Sentimentanalysen Rückschlüsse auf die Toxizität von kommunizierten Inhalten ziehen. Darüber hinaus sehen wir quantitative Inhaltsanalysen von ausgewählten Akteursgruppen, wie sie sich visueller Mittel bedienen sowie semiotische Tiefenanalysen, um diskursanalytische Schlüsse zu ziehen. Dabei beziehen sich die Analysen auf eine kleine Anzahl von Akteuren und spezifische Formen der Abwertung.
Das Ziel mit der hier angestrengten Studie war es, auf einer breiten Datenbasis aufbauend verschiedene Formen der visuellen Abwertung so untersuchen, sodass Aussagen über die Quantität von gruppenbezogenen Hass unter deutschsprachigen Hassakteuren getroffen und zugleich mit einer qualitativen Perspektive auf die konkrete Bildsprache kombiniert werden können. Um Aussagen über bildbasierte Abwertungen treffen zu können, haben wir uns auf ein spezielles Bildformat geeinigt, das wir von anderen bildlichen Darstellungen in unserem Datenset getrennt haben: das Meme. Anlehnend an Shifman definieren wir (digitale) Memes für die Zwecke dieser Studie als Bildformate, deren Sinneinheit über eine Kombination aus Text und Bild erst zustande kommt und mit dem Ziel möglichst großer Reichweite geteilt wird. In der Operationalisierung und gemeinsamen Erschließung haben wir uns auf folgende Kriterien der In- und Exklusion festgelegt:
- Inklusionskriterien: Eine Kombination aus Bild und Text; die Manipulation eines Bildes, bspw. durch visuelle Elemente, aber auch durch die Rekontextualisierumg; eine öffentliche Bezugnahme.
- Exklusionskriterien: Unbearbeitete Screenshots; Bilder / Fotos ohne Text; Text ohne Bild; Werbeanzeigen; im Bild unkommentierte Statistiken; Stockfotos; professionell erstellte Share Pics einer Organisation.
Grafiken, die nicht für sich alleine stehen können, mussten wir ausschließen, da sie ohne den Kontext des Textes nicht verständlich sind. Memes hingegen können auch unabhängig von der Textbotschaft interpretiert werden. Zugleich wird durch diese Einschränkungen eine bessere Vergleichbarkeit hergestellt. Für die Analyse wird somit der konkrete Kontext, in dem die Bilder gepostet wurden, nicht berücksichtigt. Die politische Positioniertheit der identifizierten Memes lassen sich durch ihren Ursprung in einem potenziell demokratiefeindlichen Milieu teilweise einordnen. Bis auf die ideologische Einordnung der Herkunft der Bilder werden allerdings die Urheber aus Gründen der Anonymität und der Vermeidung der Amplifikation nicht genannt.
3.a. Erstellung des Datenkorpus
Im Fokus der Analyse standen Bilder, die auf der Plattform Telegram im Zeitraum vom 01.01.2022 bis 30.06.2023 geteilt wurden. Der Datensatz bezieht sich auf das Sample von Akteuren, auf dem auch das BAG-Monitoring beruht (s. Kapitel 1a und 1b). Der Zeitraum wurde gewählt, um über eine lange Zeitspanne eine möglichst vielfältige Nutzung von Bildmaterialien zur Analyse zu nutzen. Zugleich konnten wir mit diesem Beginn des Untersuchungszeitraums einen thematischen Bias reduzieren, der durch den starken Fokus auf die Pandemie in den Jahren 2020 und 2021 entstanden wäre.

Insgesamt haben wir in unserem gesamten Monitoring 8.591.160 Bilder gespeichert, von denen nach der zeitlichen Eingrenzung und des Ausschlusses öffentlicher Chats noch eine Anzahl von 2.787.282 Bildern übrig waren, von denen wir je Ideologie (s. Kapitel 1a) 25.000 Bilder gesampelt haben. Um uns bei den verbleibenden 327.266 Bildern auf diejenigen konzentrieren zu können, die mit einer größeren Wahrscheinlichkeit eine Text-Bild-Kombination beinhalten, haben wir das Embedding der Bilder eines multimodalen neuronalen Netzwerkes (OpenAI’s CLIP Model in der Version clip-ViT-B-32) genutzt, welches auf Text- und Bildverständnis trainiert wurde, und in diesem Raum mittels eines Clustering-Algorithmus Gruppen von ähnlichen Bildern identifiziert, die die Charakteristika eines Memes (Bild-Text-Kombination) aufweisen. Mit Hilfe dieses automatisierten Schrittes konnten wir die Datenmenge noch einmal um 82,8% reduzieren, ohne großartig Gefahr zu laufen, potentiell interessante Memes auszuschließen. Durch eine Deduplikation von doppelten Bildern konnten wir weiterhin etwa 5.000 Bilder aussortieren. Für die automatische Erkennung von quasi identischen Bildern wurden abermals CLIP-Embeddings verwendet und diesmal wurden mittels Kosinus-Ähnlichkeit und einem hohen Schwellwert nur extrem ähnliche Bilder ausgefiltert.
Aus diesen vorerst bereinigten 50.956 Bildern haben wir dann für jede Ideologie zweimal 2.000 Bilder gesampelt und Kategorien ausgeschlossen, für die es nicht genügend Bildmaterial gab und die auch nicht im Zentrum unserer Analysen stehen. Somit ergab sich ein Gesamtkorpus von 40.728 Bildern, die wir für die manuelle Kodierung genutzt haben, aus denen nach manueller Untersuchung von 2.135 Memes mit einer Aspekten einer gruppenbezogenen Abwertung identifiziert haben.
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
3.b. Der Fokus auf gruppenbezogene Abwertungen: Abwertungskategorien
Der Arbeitsauftrag der BAG »Gegen Hass im Netz« ist es, Formen des digitalen Hasses auf einer datenbasierten Grundlage zu untersuchen. In unserer Forschung orientieren wir uns hierbei auf Vorurteile beruhende Formen der Abwertungen gegen Minderheiten und gesellschaftlich stigmatisierte Gruppen. Dem Konzept der Gruppenbezogenen Menschenfeindlichkeit prinzipiell folgend gehen wir davon aus, dass sich verschiedene Formen der Abwertungen einander bedingen und sich potenzieren können. Der Datenkorpus wird auf gruppenbezogene Abwertungen in Memes untersucht. Hierzu werden entsprechende Bilder in die folgenden Kategorien einsortiert, die wir so definiert haben:
- Frauenfeindlichkeit (Misogynie): Annahme einer Minderwertigkeit von Frauen, Entwertung oder Benachteiligung von Weiblichkeit (als Einstellung/Vorurteil, als Handlungen oder als Ideologie/Struktur), auch in Form von Anti-Feminismus (d.h. gegen weibliche Emanzipationsbewegung und einer vermeintlichen Auflösung traditioneller Rollenbilder) und Sexismus (stereotypische Geschlechterrollen) sowie sexualisierte Gewalt.
- LGBTQI-Feindlichkeit: Abwertung von Lesben, Schwulen, Bi- und Pansexuellen, Transgender, Genderqueer, Queer, Inter- und Asexuellen und Agender sowie ihrer Verbündeten. Menschen, die als nicht heterosexuell, binär und/oder cisgender wahrgenommen werden, werden herabgesetzt, verhöhnt oder anders diskriminiert, bis zur Gewaltandrohung- oder -anwendung.
- Rassismus: Abwertung von Menschen aufgrund ihres Äußeren, ihres Namens, ihrer (vermeintl.) Kultur oder Herkunft. Menschen werden als Teil einer vermeintlich homogenen Gruppe als verschieden konstruiert, beurteilt und hierarchisiert (weiße Menschen aus dem globalen Norden/Westen als überlegen ggü. anderen); u.a. ggü. Schwarzen Menschen, People of Color, Sinti und Roma, Indigene, Asiat*innen.
- Antisemitismus: eine bestimmte Wahrnehmung von jüdischen Personen, die sich als Hass ihnen gegenüber ausdrücken kann. Der Antisemitismus richtet sich in Wort oder Tat gegen jüdische oder nichtjüdische Einzelpersonen und/oder deren Eigentum sowie gegen jüdische Gemeindeinstitutionen oder religiöse Einrichtungen. Auch wurden Bezüge zu antisemitischen Verschwörungstheorien mit antisemitischen Bezug aufgenommen.
- Muslimfeindlichkeit: generalisierende Abwertung von Menschen, weil sie der islamischen Religion angehören; oder von Personen, die nur vermutet Muslime sind; insbesondere in Verweisen auf Kultur und Religion, oft vermittelt über eine Abwertung des Islams, die dann zur Rechtfertigung der pauschalisierten Abwertung von Muslimen dient.
Hinzu kommt, dass wir andere Formen gruppenbezogenen Hasses in einem ersten Sortierungsschritt mit einbezogen, in der Analyse allerdings aufgrund von Ressourcengründen, geringer Fallzahlen oder häufigen Kookkurenz mit einer der fünf Hauptkategorien für weitere Vertiefungen ausgeschlossen haben: Ableismus, Altersdiskriminierung, Gewichtsdiskriminierung (Fettphobie). Neben den genannten marginalisierten Gruppen, richtet sich viel Material gegen Politiker*innen und Aktivist*innen aus einer vermeintlich politisch links-grünen Einstellung. Dabei werden Memes durchaus unterschiedlich von verschiedenen Gruppen genutzt. Auch diese wurden nicht in die Analyse einbezogen, weil sie nicht den Kriterien einer sozialen Gruppe entsprechen.
Durch die verschiedenen Kodierschritte ergibt sich ein vielfältiger Datenkorpus mit vielfältigen Variablen, deren Korrelationen im Rahmen des Fokus nur begrenzt exploriert werden konnte. Die Daten sind aber auch für weitere Studien und Kooperationsgesuche abrufbereit.
3.c. Die Kodierung des Materials
Zur Klassifizierung der Memes arbeiteten wir mit einer Gruppe von neun Studierenden zusammen, die wir in einem dreistufigen Training geschult und für die Inhalte sensibilisiert haben. Bei den Schulungen wurden auch Zwischenergebnisse diskutiert und es wurde sich zu den Inhalten und Wirkungsweisen der Memes ausgetauscht. Wie andere Studien und Projekte zeigen, ist es aufgrund der komplexen Kombination von Kontexten und Bildelementen bisher kaum möglich, computerisierte Methoden zur inhaltlichen Ordnung so zu nutzen, dass ein analytischer Mehrwert herausspringt. Zu viele Inhalte würden verloren gehen oder falsch eingeordnet werden. Die Schulung der Kodier*innen hatte daher eine hohe Priorität. Da Bilder semiotisch offener als Text sind, assoziativer wirken und in dem speziellen Forschungsgegenstand häufig ironisch aufgeladen sind, haben wir eine Kommunikationsmöglichkeit per Chat angeboten, damit auf Unklarheiten im Rahmen der Tätigkeit schnell eingegangen werden konnte und diese auch für alle gleichermaßen sichtbar waren. Komplexe und voraussetzungsvolle Kodierungen wurden von dem Forschungsteam vorgenommen, das unter der Mitarbeit von Dr. Lisa Bogerts die Schritte anhand möglichst vieler Beispiele konzipierte. Für die konstruktive fünfmonatige Zusammenarbeit bedanken wir uns herzlich bei: Phoebe Genschow, Josefa Jordan, Avien Rohark, Nike Sense, Anthea Überholz, Ivan Werthmann, Leandra Zinke.
3.c.1. Schritt 1: Klassifizierung der Abwertung
Im ersten Schritt wurde das Material nach den fünf in 3.2. definierten gruppenbezogenen Abwertungskategorien geordnet, um jedes Bild dreifach zu kodieren. Mehrfachkodierungen waren möglich und sollten aufgrund der Intersektionalität der Phänomene besonders beachtet werden. Zum Kodieren wurde das Tool Prodigy genutzt, das allen Kodierer*innen jeweils dieselbe Anzahl an Bildern zur Einordnung zuwies. Die Kodier*innen hatten diese in einer Zeit von drei Wochen abzuarbeiten. Ein Validierungsschritt wurde durch die Expertengruppe im Schritt 2 wahrgenommen, wo die verschiedenen Phänomene auf ihre unterschiedlichen Narrative untersucht wurden.
3.c.2. Schritt 2: Narrativkodierung
Eine erste Erkenntnis bei der Sichtung der Memes und der Kontrolle der richtigen Einordnung ergab, dass die Bilder einer Abwertungskategorie – teilweise auch im selben Bild – verschiedene Narrative behandeln, die sich abgrenzen lassen und die Rückschlüsse darüber geben, welche abwertenden Narrative sich besonders gut in Bilder verpacken lassen. Hierzu wurde zu jeder der fünf Abwertungskategorien ein Katalog von Narrativen entwickelt, die zum einen der Forschungsliteratur zu der jeweiligen gruppenbezogenen Abwertung entnommen und zum anderen durch einen Test-Kodierung induktiv anhand des Materials entwickelt wurden. Für die Identifikation und Kodierung von Narrativen folgten wir einem bildwissenschaftlichen Ansatz, der diskursanalytisch geprägt ist.
Bei diesem Verfahren setzten sich je zwei Mitglieder des Forschungsteams an die Entwicklung der Narrative, woraufhin die anderen Mitglieder des Forschungsteams, die die Narrative nicht selbst identifiziert hatten, das Material schließlich kodierten. Mit diesem Kodierungsschritt wurde als ein Nebenprodukt auch der erste Schritt der Kodiergruppe – die Einordnung in eine gruppenbezogene Abwertungskategorie – validiert. Einerseits wurden falsch eingeordnete Memes der richtigen Kategorie zugewiesen. Andererseits wurden Bilder, die nicht in die Definition des Memes fallen, aussortiert. Die Kodierung der Narrative stellte sich als schwierig heraus. So war die Übereinstimmung in Bezug auf einzelne Narrative gegeben, aber die vielfältigen Kombinationsmöglichkeiten verschiedener Narrative, die in einem Meme enthalten sein konnten, stellten eine Herausforderung dar.
3.c.3. Schritt 3: Die Hassskala
Eine weitere Erkenntnis bei der Sichtung des Materials, die sich auch mit unseren Erwartungen an das Format des Memes selbst deckte, ist, dass die meisten abwertenden Darstellungen nicht wirklich hasserfüllt sind, sondern mit niedrigschwelligeren Formen der Abwertungen arbeiten. Um diese These zu verifizieren und ein nuanciertes , haben wir eine vierstufige Skala entwickelt. Die Kodierer*innen wurden im Hinblick auf die graduellen Unterschiede der Skala geschult und konnten Unsicherheiten an das Forschungsteam zurückmelden.
Die vier Skalenniveaus waren wie folgt definiert:
- Stereotyp: Es wird mit Klischees gespielt ohne eine explizite Abwertung.
- Abwertend: Negative Attribute werden einer Gruppe oder einem Mitglied zugeschrieben.
- Bösartig: Die Gruppe oder deren vermeintlichen Mitglieder werden als gefährlich dargestellt oder brachial abgewertet.
- Verhetzend: Der Gruppe wird Gewalt angedroht oder gewünscht, ihr Existenz wird in Frage gestellt.
Um möglichst genaue Ergebnisse zu erhalten und subjektive Verzerrungen zu minimieren, wurde jedes Meme vierfach kodiert und es war vorgesehen, einen Mittelwert zu verwenden. Aufgrund mangelnder Reliabilität wurde die Skala nicht in unsere Untersuchungen einbezogen und verweist ihrerseits auf die Subjektivität der Bewertung.
3.c.4. Schritt 4: Kodierung der Darstellung der Memes
3.c.4.a. Schritt 4a: Kodierung von visuellen Elementen
Unsere Wahrnehmung von Bild-Text-Kombinationen ist stark von Text-Elementen geprägt. Dieselben Bildelemente können eine komplett andere Aussage bekommen, wenn der begleitende Text ausgetauscht wird. Möchte man sich aber von der Textlastigkeit der meisten sozialwissenschaftlichen Forschung lösen und tatsächlich Erkenntnisse über visuelle Kommunikation erlangen, muss man auch die visuellen Elemente eines Memes analysieren, die dessen Aussage und Verbreitung beeinflussen können. Inwiefern tragen sie dazu bei, dass wir ein konkretes Meme als abwertend gegenüber einer bestimmten Gruppe einschätzen? Welche visuellen Elemente, ästhetischen Stile und rhetorischen Mittel werden verwendet, um die Bildbetrachtenden von der Botschaft zu überzeugen? Daher haben wir nach der Narrativkodierung noch einmal genau hingeschaut und möglichst unabhängig davon versucht, deskriptiv zu erfassen, was für Motive auf den Memes dargestellt sind. Dafür haben wir mehrere Arten von visuellen Elementen differenziert: Personen allgemein, Personen konkret, Objekte, Natur und Symbole. Jede dieser Elementarten beinhaltet 5-11 verschiedene Elemente. Anschließend haben wir ausgewertet, welche Elemente in welchen Abwertungskategorien und Ideologien besonders oft vorkommen und uns diese Code-Korrelationen angeschaut.
Um vermitteln zu können, welche Abwertungskategorien welche Elemente verwenden und um gleichzeitig zeigen zu können, wie ähnlich die jeweiligen Repertoires sind, haben wir ein Netzwerk aus den beiden Dimensionen erstellt. So haben wir bspw. errechnet, wie oft Antisemitismus zusammen mit dem Element »wirtschaftlich einflussreiche Person« codiert wurde, usw. So konnten wir ein Mapping über die Okkurenzen der Elemente in den Memes erstellen. Aus Darstellungsgründen haben wir alle Verbindungen, die weniger als zehn Mal vorkamen aus dem Netzwerk entfernt – genau wie die Knoten, die dadurch isoliert wurden.
Ähnlich sind wir bei dem zweiten Netzwerk vorgegangen, das die Element-Verbindungen darstellt, nur dass hier lediglich die Element-Kookkurrenzen gezählt wurden. Hier haben wir nur Verbindungen aufgenommen, die stärker als Drei waren. So können wir aus der Vogelperspektive zeigen, aus welchen Elementkompositionen die Bilder bestehen. Unsere Daten zeigen auch, dass die von uns unterschiedenen Akteure Elemente durchaus unterschiedlich benutzen, eine Einsicht, die wir aus Platzgründen nicht mehr in dem Fokus aufnehmen konnten. So sehen wir Politiker*innen aus dem deutschsprachigen Raum viel öfter in rechtsextremen Kontexten abgebildet, wohingegen Elemente wie politische und Markenlogos recht ähnlich von allen Akteursgruppen genutzt werden.
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
Netzwerk aus Ideologien und Bildelementen (Erklärung hier).
3.c.4.b. Schritt 4b: Kodierung von ästhetischen Stilen
Unsere Wahrnehmung von Bildern ist nicht nur davon abhängig was sie zeigen, sondern auch wie sie es zeigen. Zum Beispiel kann ein konservatives, modernitätskritisches Argument dadurch verstärkt werden, dass “die gute alte Zeit” auch mit visuellen Mitteln verherrlicht wird. Daher haben wir im selben Schritt auch andere visuelle Eigenschaften der Memes kodiert, die sich nicht mithilfe von dargestellten Elementen erfassen ließen. Durch eine Sichtung des Materials identifizierten wir induktiv die folgenden ästhetischen Stile, deren Einfluss auf die Botschaft des Memes uns interessierte: moderne Fotografie, historisches Bildmaterial (Foto, Malerei), Comic, Karikatur, Werbung / Fake-Werbung, Popkultur-Referenz, Statistiken/Diagramme, Screenshots, Chat-Ästhetik (Emojis etc.) und Collage.
3.c.4.c. Schritt 4c: Kodierung von rhetorischen Mitteln
Meme-Kreator*innen nutzen verschiedene Arten von “Argumenten” und Überzeugungsstrategien, um ihre Botschaft zu verbreiten. Bei der Sichtung des Materials fiel uns auf, dass ein Großteil der Memes Humor, Ironie oder Sarkasmus nutzen – wird die humorvolle und unterhaltsame Art doch teilweise sogar als Definitionsmerkmal von Memes gesehen. Dennoch wollten wir wissen, welche anderen rhetorischen Mittel verwendet werden und ob sich diese zwischen den Ideologien oder den abgewerteten Gruppen unterscheiden. Gleichzeitig entsteht z.B. neonazistischen Kanälen der Eindruck, dass ein weniger humorvoller und stärker hassbasierter Kommunikationsstil vorherrscht. Um diese subjektiven Eindrücke quantitativ zu untersuchen, haben wir folgende rhetorischen Mittel identifiziert und im selben Schritt wie die ästhetischen Stile (s.o.) kodieren lassen: (1) Humor, Sarkasmus, Ironie, Lächerlich-machen, (2) Empörung (z.B. über »Islamisierung« oder »Ausländergewalt«), (3) Gewaltandrohung/-darstellung (gegenüber der marginalisierten Gruppe), (4) Opferrolle (der Eigengruppe oder der Mehrheitsgesellschaft), (5) Überlegenheit/Stolz (der Eigengruppe oder der Mehrheitsgesellschaft)
3.d. Die Reliabilität der Daten
3.d.1. Theoretische Grundlage zur Reliabilität
Im Allgemeinen werden für die Bestimmung der Reliabilität (Zuverlässigkeit) von Kodierungen meist verschiedene Kappa Statistiken verwendet (bzw. lässt sich im vorliegenden Fall der dichotomen Kategorien zeigen, dass die geläufigsten Koeffizienten äquivalent zu Kappa Statistiken sind). Kappa bezieht sich dabei auf eine Gruppe von Methoden, bei denen die Übereinstimmung zwischen Kodierern um einen dem Zufall zugeschriebenen Faktor bereinigt wird, um somit zu ermitteln, wie groß die rein inhaltliche Übereinstimmung ist.
Mathematisch lassen sich diese Methoden wie folgt darstellen:

Inhaltliche Unterschiede ergeben sich dabei vor allem daraus, dass für die Berechnung der zufälligen Übereinstimmung unterschiedliche Annahmen getroffen werden.
Bei der Auswahl von Reliabilitätskoeffizienten für die vorliegende Untersuchung haben wir uns an wissenschaftlichen Best-Practice Empfehlungen (Holsti Reliabilitätskoeffizient, Krippendorffs Alpha) sowie der Popularität im wissenschaftlichen Kontext (Cohens Kappa) orientiert. Im Folgenden eine kurze Einordnung der dahinter stehenden Annahmen (für eine detaillierte Diskussion der Annahmen und Unterschiede verschiedener Reliabilitätskoeffizienten empfehlen wir: Zhao et al., 2013) :
- Cohens Kappa: Ist die in der wissenschaftlichen Literatur am häufigsten verwendete Kappa-Statistik. Die zugrundeliegende Annahme ist, dass beide Kodierer mit potentiell unterschiedlicher Frequenz die entsprechenden Ausprägungen kodieren. Als Schätzer für diese Verteilungen wird die beobachtete prozentuale Anteil an Ja-Stimmen für die betrachtete Kategorie herangezogen und daraus berechnet, wie groß die erwartete Übereinstimmung wäre, wenn beide einfach zufällig/blind mit dieser Wahrscheinlichkeit kodieren würden.
Anwendbarkeit: Nur anwendbar bei genau zwei Kodierer, die jedes Objekt kodiert haben. Für Fälle, in denen mehr als zwei Kodierer jedes Objekt kodiert haben und nicht zwingend jedes Objekt von jedem Kodierer annotiert wurde, haben wir mit Fleiss Kappa eine Verallgemeinerung von Cohens Kappa verwendet.
- Krippendorffs Alpha: Grundsätzlich im Falle dichotomer Entscheidung (Ja/Nein) bei zwei Kodierern eine weitere Kappa Statistik (in diesem Fall äquivalent zu Scotts Pi), wo der Unterschied zu Cohens Kappa darin liegt, dass beide Kodierer derselben Verteilung folgen. Als Schätzer wird hier gemittelt über die beiden beobachteten Verteilungen. Dementsprechend sind die Werte von Cohens Kappa und Krippendorffs Alpha auch meist sehr ähnlich und unterscheiden sich nur relevant in Fällen, wo die beiden Kodierer eine sehr unterschiedliche Prävalenz haben eine bestimmte Kategorie auszuwählen.
Anwendbarkeit: Kann mit verschiedenen Datentypen, verschiedenen Anzahlen von Kodierern und fehlenden Werten umgehen und ist somit sehr variabel einsetzbar.
- Holsti Reliabilitätskoeffizient: Unter der Annahme, dass im Kodierprozess das implizite oder explizite Wissen über Verteilungen keinen Einfluss auf die Entscheidung hat, sondern die Entscheidung rein auf Basis der Bildinhalte getroffen werden, kann der Wert für die zufällige Übereinstimmung auch mit 0 angenommen werden, so dass man die prozentuale Übereinstimmung der Kodierer erhält. Dies ist mathematisch Äquivalent zum Holsti Reliabilitätskoeffizienten oder Osgood’s Koeffizient, welche auch in vielen Forschungsarbeiten zum Einsatz kommen.
Anwendbarkeit: Kann mit verschiedenen Datentypen, verschiedenen Anzahlen von Kodierern und fehlenden Werten umgehen und ist somit sehr variabel einsetzbar.
Für das vorliegende Forschungssubjekt ist davon auszugehen, dass die Annahme, dass es keine zufälligen Übereinstimmungen gibt, die wirkliche Reliabilität überschätzt (bspw. sind Kategorien die selten vorkommen oftmals mental nicht so präsent bei der Analyse eines Bildes, weshalb deren Auswahl schneller mal vergessen wird, weshalb die Verteilung also durchaus Einfluss auf das Kodierverhalten hat). Umgekehrt ist aber auch davon auszugehen, dass die Annahme, dass das Kodierverhalten extrem stark durch angenommene Auftrittswahrscheinlichkeiten beeinflusst ist, allerdings wohl auch zu stark und führt zu einer Unterschätzung der tatsächlichen Reliabilität. Aus diesem Grund erscheint die Verwendung multipler Koeffizienten sinnvoll, um bei der Bewertung der Zuverlässigkeit der Ergebnisse auf obere und untere Schranken zugreifen zu können.
3.d.1.a Einordnung der Reliabilitätswerte
Je nach Forschungsfeld und -gegenstand können die Interpretationen der Übereinstimmungsgrade teilweise deutlich unterschiedlich ausfallen.
Beispielhaft vergleicht die folgende Abbildung verschiedene »Faustregeln«, die in der Psychiatrie und Psychologie weit verbreitet sind, um die Ergebnisse von Kappa-Statistiken in qualitative Rubriken einzuordnen.

Für unsere Zwecke sind wir in grundsätzlicher Übereinstimmung mit obigen Interpretationen davon ausgegangen, dass wir mit der Einteilung in “exzellent” (über 0.8), “gut” (0.6 bis 0.8) und “moderat” (0.4 bis 0.6) eine relativ konservative Mischform nutzen werden.
3.d.2. Reliabilitätswerte für verschiedene Kodierungsschritte
Abwertungskategorie:
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
Wie aus den Grafiken ersichtlich gibt es in diesem Fall sehr starke Unterschiede zwischen den verschiedenen Reliabilitätswerten, was unter anderem darauf zurückzuführen ist, dass mehr als 95% der Daten in diesem Schritt keinerlei Abwertungskategorie zugeordnet wurden. Damit liegt der Fall einer Klassen-Imbalance vor, bei der schon ein zufälliges Kodieren in hohen Übereinstimmungen resultieren würde. Angesichts der Wichtigkeit dieser Einordnung und der Tatsache, dass die Spannweite für den möglichen Reliabilitätswertes sehr hoch ist, haben wir entschieden die Abwertungskategorie in einem zweiten Schritt noch von jeweils zwei Experten verifizieren zu lassen und auf ein mehrstufiges Regelwerk zur Auflösung von Kodierer-Uneinigkeiten zu setzen, welches über die reine Mehrheitswahl hinausgeht. Da für den Verifizierungsschritt nur diejenigen Bilder herangezogen wurden, welche im ersten Schritt von mindestens einem Kodierer als abwertungsenthaltendes Meme eingestuft wurden, haben wir hier nicht die gleiche Klassen-Imbalance und daher auch zwischen Studenten und Experten nur bedingt vergleichbare Reliabilitätswerte.
Hassskala:
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
Aufgrund der niedrigen Reliabilitätswerte der von uns eingeführten Hassskala haben wir zusätzlich noch einmal einen Intra-Coder-Reliabilitätstest auf einer kleinen Stichprobe (145 Memes) gemacht und festgestellt, dass in 55% der Fälle derselbe Kodierer beim zweiten Kodieren einen anderen Skalenwert auswählte. Als Reaktion auf diese Ergebnisse und die Rückmeldungen der Studierenden haben wir entschlossen, die Betrachtung der Werte der Hassskala als nicht hinreichend reproduzierbar einzuordnen und daher auf eine weitere Analyse der Ergebnisse zu verzichten.
Narrative:
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
Auffällig über alle Abwertungskategorien hinweg ist, dass vor allem Narrative, die auf impliziter Symbolik oder Wissen aus Verschwörungstheorien beruhen, selbst für Experten schwierig zu kodieren sind und je nach Spezialgebiet und Annahmen über die Intention (auf Grund der Quelle der Memes) zu unterschiedlichen Kodierungen und damit niedrigeren Reliabilitätswerten führen. Als Fokusgebiet innerhalb der Narrative haben wir uns die Frauenfeindlichkeit, als die Kategorie mit den meisten Memes, ausgewählt und dort mit Hilfe eines Experten-Gremiums versucht Meinungsverschiedenheiten konsistent aufzulösen.
Darstellung der Memes:
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
In den meisten Darstellungskategorien liegen selbst die unteren Schranken für die Reliabilitätswerte im Bereich der moderaten bis exzellenten Übereinstimmung. Wie zu erwarten sind dabei Elemente, die Hintergrundwissen (bspw. Popkultur-Referenz) oder einer gewissen Abstraktion (bspw. rhetorische Stile) Bedarfen deutlich schwieriger konsistent zu kodieren als rein faktische Elemente (bspw. Personen, Objekte).
3.e. Auflösung von Kodierer-Uneinigkeiten
Wie aus den Reliabilitätswerten ersichtlich und in jedem Kodierungsprojekt üblich ist die Übereinstimmung zwischen verschiedenen Kodieren nie bei 100%. Gerade bei Themen, die von subjektiver Wahrnehmung abhängen, können trotz Kodierschulung durchaus erhebliche Unterschiede auftreten. Aus diesem Grund ist es relevant für diese Fälle eine Methodik anzuwenden, um die Kodierungen für die weitere Untersuchung aggregieren zu können. Im Folgenden gehen wir auf die von uns verwendete Methodik der Aggregation der Stimmen ein.
3.e.1. Mehrstufiges Regelwerk
Die Einteilung in die Abwertungskategorien (Rassismus, Frauenfeindlichkeit, Muslimfeindlichkeit, Antisemitismus und LGBTQI-Feindlichkeit) ist von fundamentaler Bedeutung für die vorliegende Untersuchung ist, da auch nachfolgende Schritte davon abhängig sind, weshalb für diese Kodierung ein mehrstufiges Kodierungsverfahren angewandt wurde, bei dem die Kategorien in drei unterschiedlichen Schritten jeweils durch mehrere Kodierer annotiert wurden:
- Klassifizierung der Abwertung: Ursprüngliche Einteilung in Abwertungskategorien durch zwei Studenten.
- Narrativkodierung: Neben den Narrativen wurde auch explizit die Auswahl der Abwertungskategorien von jeweils zwei Experten erneut abgefragt.
- Hassskala: Jeweils vier studentische Kodierer hatten die Möglichkeit, keine Bewertung abzugeben, wenn sie der Meinung sind, dass keine Gruppenabwertung oder kein Meme vorliegt und damit eine weitere Rückmeldung zur Abwertungskategorie zu geben.
Daraus ergab sich folgendes Regelwerk für die Auflösung von Uneinigkeiten zwischen Kodierern:
Fall 1: Bild durch beide Studenten aussortiert (kein Meme/keine Gruppenabwertung)
⇒ Aussortierung des Bildes von weiterer Untersuchung
Fall 2: Mindestens drei Stimmen von Experten und Studenten
⇒ Annahme des Votums
Fall 3: Jeweils einfaches Votum von Experten und Studenten bei gleichzeitig mindestens zweifacher Auswahl eines Hassskalenwertes in Schritt 3
⇒ Annahme des Votums
Fall 4: Studentenvotum einheitlich für “Andere Form der Abwertung” bei gleichzeitig mindestens zweifacher Auswahl eines Hassskalenwertes in Schritt 3
⇒ Annahme des Votums
Fall 5: Expertenvotum einheitlich und unterschiedlich zu Studenten
⇒ Neustart der Narrativ-Kodierung mit dieser Abwertungskategorie und dann Anwendung der Falllogik
3.e.2. Majority Vote / Mehrheitswahl
Für die Kodierungsschritte Narrativ und Darstellung des Memes wurden Fälle von Unstimmigkeiten über ein Mehrheitswahlprinzip gelöst, in dem eine Stimme nur dann gewertet wurde, wenn mindestens 50% der Kodierer dem zustimmen. Dies stellt ein in der Praxis gängiges Verfahren zur Herleitung eines einheitlichen Labels dar, kommt aber mit bestimmten Annahmen einher, dass die Unterschiede im Wahlverhalten verschiedener Kodierer nicht systematischer Natur sind (bspw. Bias oder Vorwissen), unter welchen Umständen andere Verfahren angebrachter sein können.
3.e.3 Experten-Gremium
Spezifisch für die frauenfeindlichen Narrative wurden Uneinigkeiten darüber aufgelöst, dass die Fälle einem zweiköpfigen Experten-Gremium, deren Mitglieder ursprünglich nicht in die Kodierung dieser Kategorie involviert waren, vorgelegt wurden, um in diesem Fall eine Entscheidung herbeizuführen. Mit Hilfe dieses zusätzlichen Kodierungsschrittes erhoffen wir uns die Reliabilität der Narrative in diesem Bereich noch einmal erhöht zu haben und somit entsprechende Aussage basierend auf dem Datenmaterial mit weniger statistischen Einschränkungen treffen zu können.
3.6. Hochrechnung auf Gesamtzahlen
Wie in Abschnitt 3.a. (Erstellung des Datenkorpus) beschrieben sind für die Erstellung des Datensatzes für die Kodierung mehrere Schritte vollzogen wurden um aus Kapazitätsgründen (personell und technisch) den Datensatz schon frühzeitig auf relevante (Auswahl von Bilderclustern mit meme-ähnlichen Inhalten) und repräsentative (zwei zufällige Stichproben und eine Deduplizierung) Bilder einzuschränken. Während bei der Reduktion auf relevante Bilder, die Annahme ist, dass in den aussortierten Bildern auch (fast) keine gruppenabwertenden Memes enthalten sein sollten, lässt sich bei den Filterschritten auf repräsentative Teilmengen davon ausgehen, dass die Verteilung im kodierten Datensatz ähnlich ist wie in den in diesen Schritten aussortierten Bildern. Auf der Basis dieser Annahme lässt sich dann eine Hochrechnung anstellen wieviele gruppenabwertende Memes insgesamt in den ausgewählten Ideologien im Betrachtungszeitraum geteilt wurden.
Implizit in der Annahme ist, dass jedes Bild im kodierten Datensatz, dann jeweils eine gewisse Menge an Bildern im Ursprungsdatensatz repräsentiert. Als Formel ließe sich die Berechnung also wie folgt zusammenfassen:

Hierbei steht 1/r jeweils für den Faktor, um den die Datenmenge durch die drei Filterschritte kleiner wurde (r>1). Da wir in unserer Analyse stark unterschiedliche Prävalenzen für die Nutzung von Memes feststellen konnten, aber jeweils die Ideologien paritätisch gesampelt haben, berechnen wir die Werte jeweils auf Ebene der Ideologien getrennt und summieren auf.
3.7. Regressionsanalysen
Den Einfluss von Memes und deren verschiedene Elemente auf die Viralität der Botschaften haben wir über regressionsanalytische Verfahren berechnet. In diesen Modellen haben wir die Zahl der Weiterleitungen, die eine Nachricht in den von uns im Monitoring erfassten Kanälen erhalten hat, als Indikator für Viralität herangezogen. Die Analysen basieren auf 2158 Nachrichten, in denen von uns klassifizierte Memes enthalten sind. Als Referenzdatensatz wurde eine zufällige Stichprobe von 6474 Nachrichten der 322 Kanäle gezogen, in denen auch Memes publiziert wurden. Daraus ergibt sich ein Datensatz von insgesamt 8632.
Im Mittel wurden die Nachrichten dieses Datensatzes 0.26 Mal (1.09 SD) von anderen Kanälen unseres Monitorings geteilt. Die Standardabweichung übersteigt das arithmetische Mittel, was eine rechtsschiefe Verteilung der Daten indiziert. Dieser für Zählvariablen häufige Verteilung wurde durch die negativ-binomiale Modellierung Rechnung getragen. Schließlich wurde die geschachtelte Struktur (Nachrichten in Kanälen) durch die Verwendung hierarchischer Modelle mit varying Intercepts für die Kanäle berücksichtigt. Bei beiden Modellen wurde für die Zahl der Subscriber der Kanäle kontrolliert, um Verzerrungen der Ergebnisse durch besonders reichweitenstarke Kanäle zu vermeiden. Die Berechnung der Modelle wurde mittels des lme4-Pakets durchgeführt.
Im ersten Modell wurde die Unterscheidung zwischen Nachrichten mit und ohne abwertende Memes als unabhängige Variable genutzt, wobei die Berechnung auf dem Gesamtdatensatz beruht. Im zweiten Modell wurde auf Basis des Meme-Datensatzes der Einfluss der verschiedenen Meme-Elemente (Oberkategorien) ermittelt. Die Eigenschaften dienten dabei als unabhängige Variablen.