Methodisches Vorgehen beim Monitoring (MATR Nr. 3)
1. Zur Genese der Telegram-Netzwerke
Das Monitoring der Forschungsstelle auf Telegram geht von einem akteursbasierten Ansatz aus. Das heißt, dass relevante digitale Sphären für demokratiefeindliche Kommunikation über eine Vorklassifizierung von identifizierbaren Akteuren eingegrenzt werden. Sie dienen als Startpunkte für die Sichtung breiterer Dynamiken und als Knotenpunkte für Protestmobilisierung. Ausgehend von einem Set von 269 qualitativ durch zwei Expert*innen klassifizierten Akteuren, die im öffentlichen Diskurs durch ihre Agitation Sichtbarkeit erhalten haben, wurden Charakteristika wie ideologische Ausrichtung auf Grundlage des Kommunikationsverhaltens und der bekannten Offline-Positionierungen der Akteure sowie Formen der Organisierung festgelegt, um das Feld zu sondieren. Zudem wurde die Verbindung zu breiteren Netzwerken markiert, bspw. im Falle von reichweitenstarken Accounts, die für breitere Bewegungen sprechen. Ausgehend von dieser manuellen Einordnung, die durch eine externe Expertise von Karolin Schwarz vorgenommen und von den Mitarbeitenden der Forschungsstelle geprüft worden ist, wurde ein automatisiertes, mehrstufiges Snowball-Sampling auf der Plattform Telegram durchgeführt.
1.a. Klassifizierung der Akteure
Aus dem Snowball-Sampling wurden für die Plattform Telegram 4.584 öffentlich kommunizierende Kanäle und Gruppen – im folgenden beides unter »Accounts« zusammengefasst – aufgenommen, die sich durch Weiterleitungen von plattforminternen Beiträgen in das Netzwerk einfügen. Bei Telegram haben Kanäle eine einseitige Richtung der Kommunikation (One-to-Many-Kommunikation), während in Gruppen sich jede mit jedem per Chat austauschen kann. Letztere sind in ihrer Ausrichtung divers, weswegen sie zur besseren Analyse ein weiteres Mal klassifiziert wurden, um eine Einordnung über die ideologische Ausrichtung und Verschiebung ihrer Positionierung im Diskurs treffen zu können. Hierzu wurden Accounts anhand ihrer Subscriber und Zentralität im Netzwerk sortiert und die ersten 1.400 auf ihr Kommunikationsverhalten geprüft. Hinzu kommen weitere Accounts, welche im journalistischen oder wissenschaftlichen Diskurs bereits behandelt wurden. Die qualitative Einordnung der Accounts in zuvor definierte Kategorien (s.u.) umfasste den Einblick in die letzten 20 Posts und die 20 zuletzt geteilten Links des Kanals und wurde durch das Fachwissen der Expert*innen der Forschungsstelle abgeglichen. Zudem wurden Kanäle, die sich in ihrer Selbstbeschreibung oder über die Nutzung einschlägiger Codes der Querdenken-Bewegung oder dem QAnon-Verschwöungskult zuordnen, in die jeweiligen Kategorien eingeordnet. Ähnliches gilt für Reichsbürger, die einen markanten Außenauftritt haben. Die Klassifizierung soll in der Zukunft weiter ausgebaut werden. Bezugnehmend auf bestehende Forschungsliteratur wurden in einer idealtypischen Klassifizierung die folgenden Ober- und Unterkategorien unterschieden:
Rechtsextremismus:
- Neonazismus: Dessen Anhänger*innen zeichnen sich durch einen positiven Bezug auf den Nationalsozialismus und ein rassistisch strukturiertes Weltbild aus. Viele Anhänger sind Teil von Subkulturen, in denen über Musik, Kampfsport und Hooliganismus ein Zugang zu neonazistischem Gedankengut geliefert wird.
- Reichsbürger: Eine Gruppe von Menschen, die davon ausgeht, dass das Deutsche Reich nie aufgelöst wurde und die immer noch bestehende legitime Herrschaftsform sei. Die bundesdeutsche Demokratie habe keine repräsentative Funktion, sei nicht souverän, sondern von fremden Mächten gesteuert.
- Extreme Rechte: Organisationaler Zusammenhang, der die liberale Demokratie abschaffen will. Ihre Ideologie beruht auf Ungleichwertigkeit und Autoritarismus.
- Neue Rechte: Ein strategisch denkender Kreis rechtsextremer Aktivist*innen, die über kulturelle Aktivitäten politische Macht aufbauen wollen. Ihre Wortführer*innen inszenieren sich als ideologische Vordenker*innen. Parteien und Bewegungen werden von ihren Vertreter*innen strategisch beraten.
- Populistische Rechte: Eine Sammelkategorie, in der islamfeindliche und rassistische Akteure mit einem rechten Weltbild eingeordnet werden. Es wird das ehrliche Volk gegen eine korrupte Elite gestellt. Das System solle aber demokratisch umgestürzt werden.
Konspirationismus:
- Verschwörungsideologie: Eine Oberkategorie für Akteure, die den Lauf der Geschichte durch eine Aneinanderreihung von Verschwörungen versteht, weshalb prinzipiell alles hinterfragt wird und ein schlichtes Freund-Feind Bild entsteht. Das Verschwörungsdenken übersetzt sich in politische Mobilisierung.
- Corona-Desinformation: Umfasst Akteure, die im Kontext der Corona Pandemie mit skeptischen oder leugnerischen Positionen in den öffentlichen Diskurs treten. Sie nutzen ihre öffentlichen Kanäle meist monothematisch.
- Esoterik: Eine weltanschauliche Strömung, die durch Heranziehung okkultistischer, anthroposophischer sowie metaphysischer Lehren und Praktiken auf die Selbsterkenntnis und Selbstverwirklichung des Menschen abzielt.
- QAnon: Meint einen verschwörungsideologischen Kult, der sich um falsche Behauptungen dreht, die von einer anonymen Person (bekannt als „Q“) aufgestellt wurden. Ihre Erzählung besagt, dass satanische, kannibalistische Eliten einen globalen Ring für systematischen Kindesmissbrauch betreiben. Entstanden während Trumps Präsidentschaft wird von einem tiefen Staat ausgegangen, der die Regierung kontrolliere.
- Querdenken: Mitglieder und Sympathisant*innen einer Bewegung, die sich im Kontext der Proteste gegen die Covid-19-Pandemie gegründet hat und Zweifel an der Rechtmäßigkeit der Maßnahmen zur Eindämmung mit einer radikalen Kritik an demokratischen Institutionen verbindet.
Sonstiges
- Russischer Imperialismus: Insbesondere russische Akteure, die den Aufbau eines russischen Reichs propagieren und den Krieg in der Ukraine befürworten.
- Pro-russische Propaganda: Kanäle, die pro-russische Propaganda betreiben und einseitig über den Krieg in der Ukraine berichten.
- Prepper: Eine Gruppe Personen, die sich mittels individueller oder kollektiver Maßnahmen auf verschiedene Arten von Katastrophen vorbereiten und nicht selten Phantasien des Umsturzes pflegen.
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
Anzahl der kategorisierten Kanäle in Ideologie und Ideologiegruppe. Die Farbgebung wird nach Möglichkeit in allen visuellen Elementen beibehalten.
Viele der identifizierten Kanäle lassen sich mehreren Kategorien zuordnen. So ist es nicht leicht, Verschwörungsideologien von rechtsextremen Netzwerken zu isolieren. Auch pflegen lokale Ausprägungen bestimmter Bewegungen unterschiedliche Bündnispolitiken oder nutzen bestimmte Affiliationen, um sich einem öffentlichen Stigma zu entziehen. Ausschlaggebend für die Klassifizierung war ein kumulatives Verfahren, wonach geprüft wurde, ob Akteure, die Verschwörungsmythen teilen, auch offensichtlich mit rechtsextremen Accounts verbunden sind. Ist dies der Fall, fällt die Entscheidung auf die extrem rechte Kategorie. Wenn allerdings bekannt ist, dass bspw. einzelne Influencer sich stärker ein eigenes verschwörungsideologisches Profil aufbauen, um sich von organisierten rechtsextremen Strukturen zu distanzieren oder eine bestimmte Verschwörungstheorie besonders prägnant ist, wird hier eine Unterkategorie des Konspirationismus gewählt. Um einen individuellen Bias zu reduzieren wurden die 269 Seed-Accounts von zwei Expert*innen gemeinsam kategorisiert. 145 Accounts wurden von der weiteren Auswertung ausgeschlossen, da sie nicht in das potenziell demokratiefeindliche Spektrum gehören.
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
Anzahl der betrachteten Nachrichten nach der Ideologie der Kanäle und Gruppen, für den Zeitraum dieses Trendreports.
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
Anzahl der betrachteten Nachrichten nach der Ideologie der Kanäle (ohne Gruppen) im Zeitverlauf.
Die Anzahl der Nachrichten pro Ideologie ist sehr heterogen. QAnon und andere Verschwörungsideologen senden sehr viel mehr Nachrichten als andere Ideologien.
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
Auf der X-Achse sind die Anzahl der Kanäle, welche von groß nach klein geordnet waren. Auf der Y-Achse ist der kumulierte Anteil der Gesamtnachrichten von den Top-X-Kanälen. Zum Beispiel: Die Top 14 Querdenken-Kanäle sind für 51% der Nachrichten verantwortlich.
Neben der Anzahl der Nachrichten ist es für die Interpretation der Datenauswertung interessant, welcher Anteil der Nachrichten sich auf wenige Kanäle konzentriert. Den Ideologien Prepper und Russischer Imperialismus sind nur wenige unserer Kanäle zuzuordnen, daher können auch nur begrenzt Aussagen für die Gruppen getroffen werden. Bei Reichsbürger, Neue Rechte, Pro-Russische Propaganda und Neonazismus werden über 80% der Nachrichten von den 10 Top-Kanälen gesendet. Die Dominanz dieser Akteure wird bei Datenauswertung beachtet: zum Beispiel wird für ausgewählte Analysen der zusammengefasste Rechtsextremismusbereich betrachtet.
1.b. Analyse der Kommunikationsnetzwerke im Untersuchungszeitraum
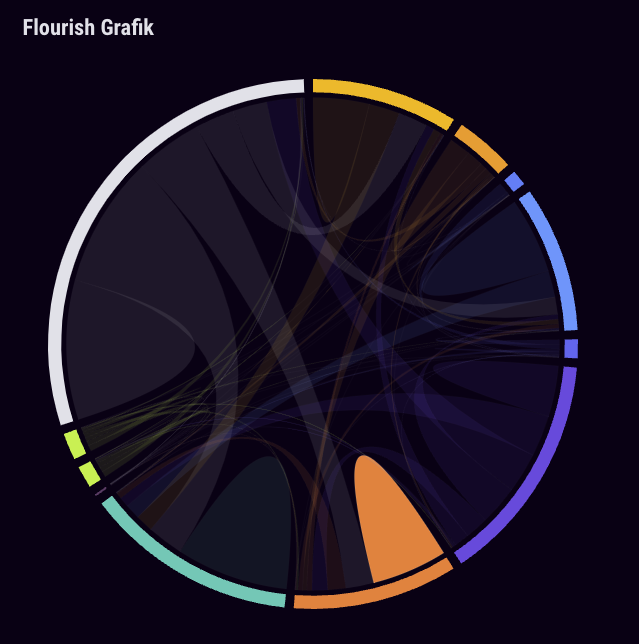
Um die Kommunikationsnetzwerke auf Telegram im Untersuchungszeitraum, also von März 2023 bis Mai 2023, zu analysieren und die Interaktionen der jeweiligen Akteursgruppen darzustellen, haben wir ein cross-sektionales Chord-Diagram erstellt. Dieses zeigt das Weiterleitungsverhalten der oben genannten politische Milieus in absoluten Zahlen ohne Berücksichtigung endogener Effekte. Netzwerkknoten sind hier die jeweiligen Milieus aggregiert.
Darüber hinaus haben wir ein Netzwerkinstanz gebildet, um auch das Weiterleitungsverhalten auf Akteursebene darstellen und analysieren zu können. Die individuellen Akteure wurden nach ihrer Ideologie eingefärbt und Verbindungen stellen deren Weiterleitungen von Telegraminhalten dar. Akteure, die wir nicht klassifiziert haben, bzw. die für uns von nachgelagertem Interesse sind, sind anonymisiert und grau hinterlegt.
2. Zur Genese der Themenmodelle
2.a. Algorithmus
Zur Berechnung der Themen haben wir die latente Dirichlet-Zuordnung genutzt (LDA). Im Gegensatz zu komplexeren Methoden – wie in (5.) beschrieben – lässt sich diese Methode mit vertretbarem Aufwand für große Textmengen einsetzen und erhält daher den Vorzug für das allgemeine Themenmodell.
Der LDA berechnet zu einem gegeben Korpus und einer gewünschten Themenzahl k eine Wahrscheinlichkeitsverteilung für alle Wörter im Korpus für jedes der k Themen. Dafür wird jedes Dokument als eine Bag-of-Words betrachtet, bei dem ausschließlich das Vorkommen einzelner Wörter von Bedeutung ist, während die Wortreihenfolge und die Satzzusammenhänge für die Klassifikation von Themen keine Rolle spielen. Jedem Dokument wird die Eigenschaft zugeschrieben, aus mehreren latenten Themen zu bestehen. Ein Thema ist schließlich durch eine Wahrscheinlichkeitsverteilung von Wörtern definiert.
Das prinzipielle Verfahren beginnt mit der zufälligen Zuweisung von jedem Wort im Korpus zu einem Thema. Danach folgt eine Schleife über alle Wörter in allen Dokumenten mit zwei Schritten:
- Mit der Annahme, dass alle anderen Wörter außer das aktuelle korrekt ihren Themen zugeordnet sind, wird die bedingte Wahrscheinlichkeit p(Thema t | Dokument d) berechnet: Welche Themen kommen im Dokument wahrscheinlich vor? Das zurzeit betrachtete Wort passt mit höherer Wahrscheinlichkeit zu diesen Themen.
- Berechnung der bedingten Wahrscheinlichkeit p(Wort w | Thema t): Wie stark ist die Zugehörigkeit des Wortes zu den Themen?
- Aktualisieren der Wahrscheinlichkeit, dass ein Wort zu einem Thema gehört: p(Wort w ∩ Thema t) = p(Thema t | Dokument d) * p(Wort w | Thema t).
Durch mehrere Iterationen über alle Wörter im Dokument erreicht der Algorithmus eine stabile Konfiguration von Wortwahrscheinlichkeitsverteilungen für k Themen.
2.b. Datengrundlage und Preprocessing
In die Themenmodellberechnung sind alle Nachrichten der in Abschnitt 1.a genannten Kanäle eingegangen. Es erfolgte die Bearbeitung mit folgender Preprocessing-Pipeline:
- Filtern der NA-Texte: Nachrichten, die nur aus Medien-Dateien bestehen, ohne weiteren Text zu enthalten, wurden in der Themenmodellierung nicht berücksichtigt.
- Filterung auf den Zeitraum vom 1. März 2022 bis 31. Mai 2023.
- Filter auf > 50 Zeichen: Eine erste Filterung auf die Mindestanzahl von Zeichen ist nötig, um eine Spracherkennung durchzuführen.
- Filter auf deutschsprachige Nachrichten: Dafür wurde die Bibliothek Polyglot verwendet.1
- Preprocessing der Texte
- Entfernung der URLs mittels Regular Expressions.
- Lemmatisierung, also die Reduktion der Wortform auf ihre Grundform, mit spaCy bei Verwendung der Pipeline de_core_news_lg.2
- Entfernung von Stoppwort-Lemmata anhand verschiedener Stoppwortlisten.
- Entfernung von Wörtern mit dem Vorkommen < 8.
- Entfernung Sonderzeichen.
- Filter auf 1-n Kanäle: Die Nachrichten innerhalb der Chatkanäle behandeln oft keine Themen im gewünschten Sinn und verschlechtern die Nutzbarkeit des Themenmodells. Die Texte werden dennoch später klassifiziert, um die Ergebnisse explorativ nutzen zu können.
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
2.c. Modellberechnung und Themenbestimmung
Für das Training des Modells haben wir das Python-Paket tomotopy genutzt.3 Der wichtigste Parameter beim Training des LDA ist die Anzahl der zu findenden Themen. Dieser Prozess ist mit einigen Freiheitsgraden behaftet, der schließlich auf einer Interpretationsleistung der Forschenden basiert. In der Regel werden Themenmodelle mit einer Reihe von verschiedenen Themenzahlen trainiert und für jedes Thema wird eine Themenkohärenz berechnet. Anhand dieser wird abgeschätzt, wie viele Themen in etwa genügen, um das Themenspektrum im Korpus abzudecken. In diesem Trendreport haben wir uns auf die gesammelte Erfahrung aus dem vorherigen Trendreport verlassen und erneut 120 Themen verwendet. Der vollständigkeitshalber wird die Herangehensweise im folgenden Paragraph erneut beschrieben.
Es wurden zwei gebräuchliche Metriken für die Modellkohärenz berechnet, welche im folgenden Graph zu sehen sind.4
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
Die Kurven der Koherence geben dem Anwender einen Anhaltspunkt für die Bestimmung der Modellgüte zur Hand, aus dem sich in diesem Fall keine eindeutige Empfehlung ableiten lässt.5 Prinzipiell ist es bei einer großen Menge von Daten möglich, die Anzahl der Themen relativ frei zu wählen, mit dem naheliegenden Trade-Off zwischen potentiell unspezifischen Themen bei einer kleinen Anzahl von k und spezifischen, aber teilweise redundanten Themen bei großer Anzahl von k. Wir haben uns für die große Themenanzahl k=120 entschieden, da somit eine große Anzahl der aus substantieller Sicht erwartbaren Themen Niederschlag im Modell finden.6
Allerdings benötigt die qualitative Einordnung der Themen dementsprechend viel Zeit. Für diese wurden im Vier-Augen-Prinzip die 25 Wörter mit höchster Wahrscheinlichkeit und die 25 Wörter mit auf gesamtwordhäufigkeit-normierter Wahrscheinlichkeit betrachtet. Erstere zeigen die generelle Beschaffenheit des Themas, wobei zweitere die spezifischen Wörter zeigen, welche die Abgrenzung zu anderen Themen deutlich machen.
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
Bei der Verwendung von einem LDA-Themenmodell gilt es zu beachten, dass der Algorithmus keine Möglichkeit hat, Dokumente oder Wörter auszuschließen. Das heißt, jedes Dokument bekommt Themen und jedes Wort wird Themen zugeordnet. Zwangsläufig entstehen auch Wortverteilungen, welche sich nicht einem Thema im herkömmlichen Sinne zuordnen lassen, wie beispielsweise das Thema Sprache_Füllwörter1 (siehe Wordclouds). Eine weitere Schwierigkeit sind überlappende Themen wie die zwölf Themen rund um Corona. Hier ist es für eine aussagekräftige Interpretation essentiell, eine sinnvolle Einordnung der Themen vorzunehmen. Dafür haben wir in einem iterativen Prozess die Themen in acht Themenkomplexe und 36 Oberthemen aufgeteilt.
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
Die Entwicklung aller Themen wird in folgender Grafik gezeigt:
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
Für eine erste Einschätzung der Güte der Einteilung diente die Korrelationsmatrix zwischen den Wortwahrscheinlichkeiten der verschiedenen Themen. Die Achsen sind zur Übersichtlichkeit mit den Themenkomplexen gekennzeichnet. Jede Zeile zeigt die Korrelation für ein Thema mit allen anderen Themen. Ein weißer Punkt bedeutet vollständige Korrelation. Je dunkler der Punkt, umso weniger korrelieren die Themen. Es lassen sich Cluster von Themen erkennen, die uns bei der Einteilung als Stütze dienen können. Beispielsweise befinden sich etwa in der Mitte der Diagonale der Themenkomplex Ukraine-Russland.
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
2.d. Validierung der Themen
Die Erkennung eines Themas in einem Dokument ist instabil für kürzere Dokumente.7 Zur Annäherung an eine Stabilitätseinschätzung in Abhängigkeit von der Dokumentenlänge führten wir folgende Untersuchung durch:
- Auswahl eines zufälligen Samples von 25.000 Dokumenten mit einer Lemmata-Anzahl von über 100: Die Themenermittlung zu diesen Texten wird als korrekte Referenz gesehen, da der LDA für diese Textlänge sehr stabil ist.
- Wir betrachten verschiedene Textlängen von n = 10 bis 100 in Zehnerschritten: Es werden für jedes Dokument n Lemmata aus der jeweiligen Ursprungsmenge gesampelt. Für die entstehende Wortmenge wird ein Thema inferiert, so dass eine neue Themenzuweisung für die 25.000 Dokumente entsteht. Für ein stabiles Themenmodell sollte diese Zuweisung möglichst nahe an der Referenz aus Schritt 1 liegen.
- Zehnfache Wiederholung von Schritt 2 und Aggregation der Ergebnisse: Das resultierende Thema wird über den Modalwert ermittelt. Zusätzlich werden die Oberthemen und Themenkomplexe bestimmt, um zu sehen, ob das Thema in der weiter gefassten Definition noch erfasst wird. Schlussendlich wird die euklidische Distanz zwischen den Wortwahrscheinlichkeitsverteilungen des Referenzthemas und des gesampleten Themas ermittelt, welches als Abstandsmaß unabhängig von der Kategorisierung ist und daher verlässlicher.
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
Die Ellenbogenmethode legt nahe, dass die Anwendung des Modells für Texte ab der Lemmatalänge von 20 einen guten Trade-Off zwischen Dokumentenanzahl und dem zu erwartenden Fehler bei der Themenbestimmung kürzerer Texte darstellt. Bei den Themenkomplexen sind im Schnitt nur 16 Prozent Fehler bei dieser Dokumentenlänge zu erwarten. Vor dem Hintergrund, dass unsere Auswertung zumeist auf stark aggregierten Daten basiert, ist dieser Fehleranteil vertretbar.
Weiterhin interessant ist die Beobachtung, dass der Fehler selbst bei der gesampelten Dokumentenlänge von 100 bei zehn Prozent für die Hauptkategorien liegt. Dies verdeutlicht, dass selbst ausreichend lange Dokumente eine gewisse Unsicherheit in dem zugewiesenen Thema beinhalten. Indem die Anzahl der Fehlzuweisungen aggregiert und durch die Prävalenz geteilt wird, bekommen wir einen normierten Prozentfehler für die Kategorien.
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
Aggregiert ergeben sich für die Hauptkategorie folgende Fehlerprozente: Sonstiges 19,8%, Politik 11.5%, Weitere Themen 11.3%, Protestbewegung 10.5%, Weitere Themen 10.1%, Verschwörung 8.2%, Ukraine-Russland 6.9%, Corona 4.6% und Esoterik 3.3%. Der häufigste Fehler ist der Übergang von Sonstiges zu anderen oder umgekehrt. Dies ist ein nachvollziehbarer Fehler, da Sonstiges die Sprachmuster enthält und diese zu einem Teil in jedem Text vorzufinden sind. Insgesamt sind das gute Werte. Für die Interpretation sollte dennoch beachten werden, dass die Themen Politik und Protestbewegung im Vergleich zu inhaltlich klarer abgrenzbaren Themen eine höhere Fehlerquote mit sich tragen.
3. Zur Analyse der Twitterdiskurse
Um zu analysieren, wie der sich der Hashtag #Stolzmonat entwickelte und welche Akteure hier einen wesentliche Rolle spieleten, haben wir alle Tweets zum Hashtag bis einschließlich 21. Juni mit dem Tool Twitter-Explorer8 heruntergeladen. Um auch das Vorspiel zu erfassen und die Schlüsselakteure, die hinter der Aktion standen, haben wir auch die initialen Tweets eine Woche vor dem eigentlichen Aktionszeitraum erfasst. Insgesamt konnten wir so rund 899.100 Tweets von 46.000 Nutzer*innen zusammentragen.
Für unsere Analyse haben wir sogenannte Retweetnetzwerke generiert. Wenn Twitternutzer*innen Inhalte anderer Nutzer*innen durch Retweeten teilen, wird dies als Verbindung im Netzwerk dargestellt. Hieraus kann man durchaus eine inhaltliche Affirmation ableiten, da sich die Gepflogenheit etabliert hat, Nachrichten aus dem gegnerischen politischen Lager lediglich mittels Screenshot zu teilen, um diesen keine größere Reichweite zu verschaffen. Eingefärbt haben wir die Akteure mittels des Louvain Community Detection-Algorithmus9 – hier also nicht anhand deren Ideologie, sondern ihres Retweet-Verhaltens. Dabei werden Gruppen von Akteuren – oder in diesem Fall Twitter-Nutzer*innen – automatisiert detektiert, wenn diese sehr eng miteinander verbunden sind, bzw. sich übermäßig häufig miteinander kommunizieren. So können wir relativ schnell die Modularität des Netzwerkes bewerten und Cluster, bzw. Nutzergruppen ausfindig machen.
Den groben Inhalt der Stolzmonatkampagne geben die Top 50 Hashtags wieder. Diese haben wir mit dem R-Paket quanteda10 aus den Daten extrahiert und in Verbindung gesetzt, sobald sie im gleichen Tweet verwendet werden. Die Dicke der Verbindungen stellt die Häufigkeit dieser Kookkurrenz dar. Analog dazu haben wir die Top 50 der meistgenannten Twitter-Nutzer*innen extrahiert und in Verbindung gesetzt.
Um Koordinierung der einzelnen Twitter-Nutzer*innen zu untersuchen, haben wir die Tweets mit dem Coordination Network Toolkit11 untersucht. Hierzu haben wir diverse Typen der Koordination (von Co-retweet, Co-tweet, Co-similarity, Co-link, Co-reply und Co-post) in verschiedenen Zeitintervallen durchgespielt. Dabei wird die Häufigkeit der gleichen Twitterinteraktion gemessen, also wenn bspw. zwei Nutzer*innen innerhalb einer Sekunde denselben Tweet teilen. Bot-ähnliches Twitterverhalten wird in der Literatur meist mit einem Zeitintervall von einer Sekunde oder weniger nachgewiesen und wenn die User*innen sehr oft die gleiche Interaktion im selben Zeitintervall ausführen.12 Dieses Bot-ähnliche Verhalten konnten wir beim #Stolzmonat nicht beobachten. Jedoch führten mehrere Nutzer*innen wiederholt dieselbe Interaktion innerhalb von 60 Sekunden aus, was auf geteilte Accounts hinweist.13
Um den Kampagnenverlauf darzustellen, haben wir außerdem aus den Tweets Zeitreihen gebildet, die nach Tagen untergliedert sind.
4. Zur Genese der Monetarisierungsdaten (ohne Kryptowährungen)
In regelmäßigen Abständen erhebt die Forschungsstelle alle URLs und extrahiert die Domains. Zur Erhebung von Finanzierungsquellen wurden zunächst die Links der meist genutzten Linkshortner aufgelöst. Bit.ly-Links, 64 Tsd. Nachrichten, und cutt.ly-Links, 9 Tsd. Nachrichten, wurden mit einem Get-Call von der Python Bibliothek request aus aufgelöst. Tinyurl.com-Links lassen sich nicht auf diese Weise auflösen und es wurden alle Links, welche mehr als 10 mal aufgetreten sind, mit Selenium aufgelöst. Lmy.de-Links konnten nicht aufgelöst werden und werden aus der Analyse ausgeschlossen. Damit wurden etwa 91 Tsd. Shortener-Links aufgelöst und etwa 30 Tsd. Shortener-Links ignoriert. Weiterhin wurden amzn.to – Links aufgelöst.
Für die Identifikation von Finanzierungsquellen wurden 2 Methoden gewählt:
1) Häufigste Domains auf Shops überprüfen, dabei gefunden:
a) Streaming-/Videoplattformen: YouTube, Rumble, Odysee, Bitchute, Dlive, Disclose.tv
b) Shops mit Affiliates: Kopp Verlag, Amazon,
c) Spendenplattformen: Paypal
2) Mögliche Affiliate Links und weitere Shops oder Spendenplattformen suchen. Die Syntax von Affiliatelinks unterscheidet zwischen verschiedenen Shops. Wir haben Links gesucht die folgendes enthalten:
a) “ref”, “partner”, “aff” für Affiliates
b) “produkt”, “product”, “kaufen”, “collection”, “store”, “shop” für Shops
c) “donate”, “spende”, “support”, “untersützen” für Spenden
Wir haben aus allen identifizierten Shops eine Regex gebaut und das Ergebnis als Grundlage für die Datenanalyse genutzt. Für einige der Plattformen ist es wichtig zu unterscheiden, ob es sich um Affiliate-Links handelt oder Links ohne Finanzierungsübersicht. Für die Analyse der Kooperation war es ebenso notwendig, die Affiliate-Syntax beziehungsweise die Logik der URLs nachzuvollziehen, um die ID bzw. den Profiteur des Links herauszubekommen. In der folgenden Tabelle sind die einzelnen Logiken beschrieben. Für viele Domains ist es nützlich, die URLs an den ‘/’ zu teilen. In der Tabelle wird auf eine URL wie folgt bezogen: domain.xx/split1/split2/split3. Für die Fälle, in denen die Logik der Affiliate-Syntax nicht nachvollzogen werden konnte, wurden nur komplett übereinstimmende URLs als übereinstimmende Referenz gewertet.
Klicken Sie auf den unteren Button, um den Inhalt von Flourish zu laden.
Die Extraction der IBAN erfolgte mittels Regex (“\\b[a-z]{2}(?:[ ]?[0-9]){18,20}\\b”).
Zur Auswertung der Kooperation wurden jeweils für jeden ID bzw. Profiteur von den extrahierten Links das erstmalige Auftreten als Quelle gewertet. Nachfolgendes Auftreten wurde als Kooperation zwischen den Ideologien dieser Kanäle und der Ideologie des Quellkanals gewertet. Nachteilig an dieser Methode ist, dass die Quelle falsch identifiziert wird, wenn das erste Auftreten in einem Kanal außerhalb unseres Monitorings auftritt. Allerdings ist anzunehmen, dass in den meisten Fällen die ersten Kooperation Ideologie nah sind, so dass der Fehler nicht allzu groß ist. Problematischer ist das große Auftreten von Monetarisierungslinks innerhalb von signaturähnlichen Textbausteinen in den Nachrichten. Diese lassen sich nicht verlässlich entfernen. Die entwickelte Kooperationsmetrik korreliert durch diese Nachrichten, aber mit dem generellen Teilungsverhalten der Kanäle. Daher ist Kooperation hier stets im weiteren Sinne zu verstehen.
Erhebung der Monetarisierung über die Streamingplattform DLive: Auf dieser Plattform besteht die Möglichkeit Streamer*innen die Plattform-eigene Währung Zitronen zu schenken, welche dem Gegenwert von $ 0.012 US Dollar entspricht.14 Die Top10 der Spender*innen im letzten Monat und aller Zeit ist öffentlich einsehbar. Aus dem Monetarisierungsdaten wurden alle Links zu Dlive ermittelt und mittels Selenium wurden die Spender*innen und die getätigten Beträge ermittelt. Zusätzlich wurde noch eine Schätzung vorgenommen, wie viel Spenden außerhalb der Top10 zustande gekommen sein könnten. Für die Schätzungen wurden 0.01 x des Betrag des zehnt höchstens Spenders mal 20 % der Abonnent*innenzahl gerechnet.
5. Zur Genese der Kooperations- und Transaktionsnetzwerke bei Kryptowährungen
Zunächst haben wir die rund 1500 Telegramnachrichten der Kanäle, die wir manuell nach Ideologien kodiert haben, mit regulären Ausdrücken durchforscht, um Bitcoin, Ethereum, Monero und Cardano Adressen zu finden. Dies haben wir auf Originalnachrichten beschränkt, um Falschzuordnungen zu vermeiden. Weitergeleitete Nachrichten wurden aus diesem Grund nicht berücksichtigt, da sie nur die Analyseschärfe verringert hätten. Schließlich leiten Akteure oft Nachrichten aufgrund ihres Inhalts weiter und nicht wegen des enthaltenen Spendenaufrufs. Um mögliche false-positives (bspw. in URLs) zu eliminieren, haben wir deren Check-Sum gebildet und diejenigen entfernt, die keine valide Wallet-Adresse waren. Hierdurch konnten wir 89 Bitcoin-, 60 Ethereum-, 10 Monero- und eine Cardano-Adresse ausfindig machen. Aus ressourcentechnischen Gründen haben wir uns bei der Analyse auf Bitcoin und Ethereum beschränkt. Da einige Akteure auch Bewegungen auf sehr großen oder populären Konten kommentiert haben, sind wir die jeweiligen Nachrichten, die die Adressen enthielten, manuell durchgegangen und haben nur Konten aufgenommen, die einen Spendenaufruf enthielten.
Im nächsten Schritt haben wir alle Transaktionen der einzelnen Adressen aus den jeweiligen Blockchains extrahiert. Hierzu haben wir das R-Paket Rbitcoin15 und den etherscan.io-API-Clienten etherscanr16 genutzt. Daraufhin haben wir die Wallets, die nicht aktiviert oder keine Transaktionen durchgeführt hatten, entfernt. Da uns nur die eingehenden Transaktionen interessieren, haben wir die ausgehenden aus den Daten herausgefiltert und den Gegenwert in Euro für die eingehenden Transaktionen bestimmt, indem wir diese mit den jeweiligen Tageskursen umgerechnet haben. So können wir den Gesamtbetrag der eingehenden Assets auf die einzelnen Konten präzise bestimmen. Den jeweiligen Wallets haben wir ferner die potentiellen Inhaber*innen zugeordnet, indem wir die Nachrichten manuell durchgegangen sind. Schließlich haben wir diejenigen Transaktionen, die bei otx.me als Unspent Transaction Outputs (UTXOs) geflaggt waren, extrahiert und aus unserem Sample entfernt.
Um die Kooperation beim Werben um Krypto-Spenden zu untersuchen, wurden bipartite Netzwerke aus den jeweiligen Wallets und den Kanälen, die auf sie verweisen, gebildet. Um das Transaktionsgeschehen nachvollziehen zu können und etwaige Finanziers der Szene, sowie Kontobewegungen unter den Akteuren zu identifizieren, haben wir Transaktionsnetzwerke aus den uns bekannten Konten und den Konten, von denen diese Assets erhielten, gebildet. Da einige Konten auch Transaktionen mit Kryptobörsen tätigen, haben wir ferner alle Knoten mit einem Outdegree von mehr als eins manuell recherchiert und wenn möglich den jeweiligen Börsen zugeordnet. Für die Ethereum-Netzwerke war dies wesentlich einfacher, da hier mehr öffentlich zugängliche Daten im Netz kursieren, bzw. die Konten von etherscan.io als Börse geflaggt waren. Bei einigen Bitcoin-Wallets war keine öffentliche Information über die Inhaber*innen zu finden, weswegen wir diejenigen Wallets, die einen unnatürlich hohen Kontostand oder unnatürlich hohe Transaktionsraten aufwiesen als »unknown natural« gelabelt haben. Diese sind aller Wahrscheinlichkeit nach Kryptobörsen oder börsenähnliche Konstrukte. Lediglich neun Konten mit einem höheren Outdegree als eins hatten übliche Transaktionsraten und Kontostände. Diese haben wir als »unknown natural« gelabelt.
- Siehe online hier. Dabei wurde die Sprachvorhersage nur akzeptiert, wenn das Attribut reliable den Wert True vorwies. Um eine potentiell zu restriktive Filterung zu erkennen, wurden zufällig 500 aus den herausgefilterten Texten gezogen und manuell geprüft. Davon waren fünf fälschlicherweise aussortiert. Diese Fehlerquote stellt kein Problem für die Ergebnisse des LDAs dar. Mögliche Falsch-Positive wurden nicht überprüft.
- Siehe online hier.
- Siehe online hier.
- u_mass misst die paarweise Kookkurrenz in Dokumenten des Korpus von den Top-n der wahrscheinlichsten Wörtern zu jedem Thema. Ein höherer Wert ist besser. c_uci misst die Kookkurrenz in einem wandernden Fenster. Ein höherer Wert ist besser.
- Die Themenmodelle wurden aus Kapazitätsgründen lediglich einmal trainiert. Mit mehreren Durchläufen würde sich Dellen in der Kurve ausbessern lassen. Dies würde allerdings keine andere Schlussfolgerung nach sich ziehen.
- Als Beispiele seien Verschwörung_Great_Reset und Migration genannt.
- Eine Daumenregel besagt, dass LDAs bei etwa 50 Wörtern stabil sind. Durch das durchgeführte Preprocessing ist die durchschnittliche Information pro Wort höher, so dass 20-30 Wörter der Daumenregel entsprechen würden.
- Armin Pournaki u. a., »The Twitter Explorer: A Framework for Observing Twitter through Interactive Networks«, Journal of Digital Social Research 3, Nr. 1 (29. März 2021): S. 106–18, https://doi.org/10.33621/jdsr.v3i1.64.
- Vincent D. Blondel u. a., »Fast Unfolding of Communities in Large Networks«, Journal of Statistical Mechanics: Theory and Experiment 2008, Nr. 10 (Oktober 2008): S. P10008, https://doi.org/10.1088/1742-5468/2008/10/P10008.
- Kenneth Benoit u. a., »quanteda: An R package for the quantitative analysis of textual data«, Journal of Open Source Software 3, Nr. 30/774 (2018), doi:10.21105/joss.00774.
- Timothy Graham und Queensland University of Technology Digital Observatory, »Coordination Network Toolkit«, , (2020). https://doi.org/10.25912/RDF_1632782596538.
- Siehe bspw. Franziska B. Keller u. a., »Political Astroturfing on Twitter: How to coordinate a disinformation Campaign«, Political Communication, Nr. 37(2) (2020), S. 256-280.
- Timothy Graham, u. a.,»Like a virus: The coordinated spread of coronavirus disinformation«, Centre for Responsible Technology, (2020), online hier: https://apo.org.au/node/305864.
- https://community.dlive.tv/about/welcome-letter/.
- Online hier: https://github.com/jangorecki/Rbitcoin.
- Online hier: https://github.com/dirkschumacher/etherscanr.